TALP Performance metrics
TALP can collect metrics from both the host (CPUs) and GPUs. These metrics provide insight into how computational resources are utilized, where bottlenecks occur, and how different programming models (MPI, OpenMP, CUDA, HIP, etc.) interact.
For clarity, the metrics are divided into two categories:
Host-only metrics: capture performance for CPU-only executions, including MPI, OpenMP, or hybrid MPI+OpenMP applications.
Hybrid CPU+GPU metrics: capture performance for executions that involve both the host and GPU runtimes. This includes CUDA, HIP, and combinations with MPI or OpenMP.
Host-only metrics
The performance metrics reported by TALP are derived similarly as the POP metrics.
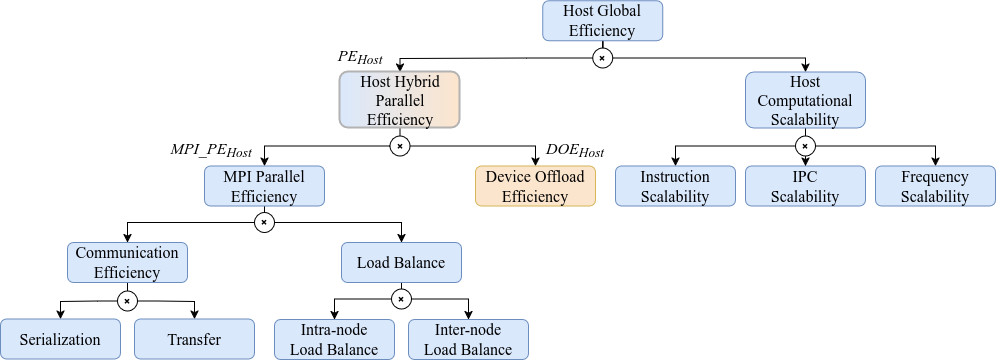
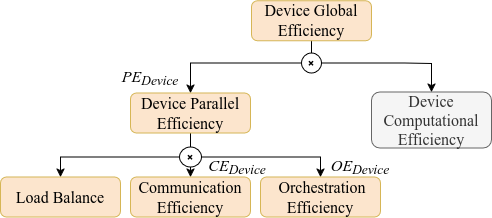
The figure below shows the hierarchy of metrics which categorises efficiency-losses into programming-model specific categories.

TALP is able to generate these metrics for every region that is added.
Below, we will briefly explain how the metrics are computed.
For simplicity, we assume that all MPI processes run with the same number of OpenMP threads, and that all OpenMP threads execute the same parallel regions.
Note
TALP is actually able to handle applications where these conditions don’t hold, but we chose to keep the derivations as clear as possible.
First we introduce some common notion which we use to classify the execution time. Let \(N\) be the number of MPI processes, \(M\) be the number of OpenMP threads per process and \(P:\) the number of parallel regions of each thread.
Classification of execution time
With this we can define \(T_{i,j}\) to be the total time spent in the \(j\)-th OpenMP thread of the \(i\)-th MPI process. We classify time spent by threads in three categories:
\(U\), doing useful computation
\(C\), MPI communication
\(I\), idle OpenMP threads and time spent within the OpenMP runtime.
Let \(T^{k}_{i,j}, \forall k \in \{U, C, I \}\) be the time spent in the \(k\)-th category for the given thread and process.
Therefore,
Let \(T^k_{i}\) be the average thread time per process such that:
We further subdivide the time spent by idle threads (\(T^I\)) into three subcategories:
\(I_\mathrm{serial}\), outside parallel regions;
\(I_\mathrm{lb}\), waiting for the slowest thread of each parallel region; and
\(I_\mathrm{sch}\), all other time spent idling inside parallel regions.
Let \(T^I_{i,j,p}\) be the idle time inside the \(p\)-th OpenMP parallel region of the \(j\)-th thread of the \(i\)-th process.
Let \(T^{I_\mathrm{serial}}_{i}\) be the average thread time spent by process \(i\) outside OpenMP,
We define \(T^{I_{lb}}_{i}\) to be the average thread time spent by process \(i\) waiting for thread synchronisation due to load imbalance,
\(T^{I_\mathrm{sch}}_{i}\) is the average thread time spent by process \(i\) lost due to scheduling,
\(T^k\) be the average process execution time such that:
OpenMP metrics
Let \(\mathrm{OMP}_\mathrm{Serial}\) (OpenMP Serialization Efficiency) represent the time lost because OpenMP was not running a parallel region.
This metric is used to account for regions not parallelized with OpenMP.
Let \(\mathrm{OMP}_\mathrm{LB}\) (OpenMP Load Balance Efficiency) represent the time lost in idle OpenMP threads within a parallel region due to an uneven distribution among its threads.
Let \(\mathrm{OMP}_\mathrm{Sched}\) (OpenMP Scheduling Efficiency) represent the time lost in idle OpenMP threads within a parallel region not caused by load imbalance.
Let \(\mathrm{OMP}_\mathrm{Eff}\) (OpenMP Parallel Efficiency) be the efficiency considering only time when OpenMP threads are idle as lost,
MPI metrics
In the hybrid model, the MPI metrics are redefined as:
Please note that, when \(M = 1\) (executions with one OpenMP thread or without OpenMP all together), \(\mathrm{Hyb}_\mathrm{Eff} = \mathrm{MPI}_\mathrm{Eff}\).
Hybrid parallel efficiency
Let \(\mathrm{Hyb}_\mathrm{Eff}\) (Hybrid Parallel Efficiency) be the efficiency considering both time in MPI calls and time in idle OpenMP threads as lost:
Interaction between MPI and OpenMP metrics
There are certain situations in which threads are idling waiting for an MPI communication to finish.
On the OpenMP side, communication and computation can be overlapped to mitigate this inefficiency.
On the MPI side, reducing the time of the communication would also reduce the time that OpenMP threads are waiting.
Despite both programming models might be at fault, the current formulation of the hybrid model classifies this situation under the OpenMP metrics.
There is an ongoing work to incorporate interactions between MPI and OpenMP to the hybrid efficiencies model.
Host and GPU metrics
To obtain hybrid CPU+GPU metrics, DLB must be used with one of the available GPU plugins. See NVIDIA GPU executions and AMD GPU executions for more information.
The figures below show the hierarchies of metrics for hybrid executions, now split to distinguish between host and GPU domains, while still categorizing efficiency losses according to the relevant programming models.